Freeware-версия является экспериментальной и содержит ряд ограничений.
Скачать текст программы, демонстрирующий применение процедур с повторным входом.
Может компилироваться GNU C++ или Microsoft Visual C++. Для работы с директивами, связанными с распараллеливанием,
необходима поддержка OpenMP. Компиляция программы:
Reenterable reent.cpp reent1.cpp
g++ -o reent reent1.cpp -lm -fopenmp --std=c++0x -fgnu-tm
Теория. Планирование повторного входа в процедуру в языках высокого уровня
Предлагается ввести в алгоритмические языки высокого уровня
формализм процедуры
с планированием повторного входа. Такие процедуры облегчают программирование некоторых алгоритмов,
традиционно реализуемых с применением стека/очереди/дека. В 1,5-2 раза сокращается объем реализующего
кода (см. примеры), более логичной
и естественной становится запись алгоритма. Легко реализовать распараллеливание такого алгоритма
по типу "портфель задач" (task pool), когда формируется множество подзадач, из которой процессоры
системы "забирают" задачи на исполнение.
Вводится понятие цепи процедур, в которой легко организовать стадийную или
векторную обработку данных. Это позволяет выявить скрытый векторный или конвейерный параллелизм
и соответствующим образом распараллелить решение задачи на многопроцессорной или многоядерной
вычислительной системе.
Процедура с планированием будет отличаться от обычной
наличием плана исполнения, элементами которого (этапами) являются векторы значений
параметров для очередного вызова процедуры. Рассмотрим два варианта реализации плана:
динамический и статический.
1. Динамический план
В данном случае любой явный (в том числе рекурсивный) вызов процедуры
с повторным входом создает новый план, который первоначально содержит единственный элемент
(начальный этап) - вектор значений параметров, указанных при вызове процедуры. В ходе
исполнения процедура может включить в план один или несколько дополнительных этапов
с указанием соответствующих значений параметров процедуры. Включение в план может
производиться в соответствии с одной из основных стратегий: "очередь", что соответствует
вставке (планированию) в конец плана, или "стек", что соответствует вставке (планированию)
в начало плана. Потребность в тех или иных операциях вставки определяется алгоритмом.
При выходе из процедуры производится проверка плана: если план пуст, то осуществляется
возврат в вызывающую программу, в противном случае из начала плана извлекается очередной
этап, соответствующие ему значения параметров помещаются в параметры процедуры и производится
повторный вход (переход в начало процедуры).
2. Статический план
Если процедура имеет статический (постоянный) план, то его исполнение может быть
остановлено (с выходом из процедуры) и возобновлено при следующем входе в процедуру. Возможны две
модификации статического плана:
а) глобальный (единый на всех уровнях рекурсивного вызова),
б) локальный (индивидуальный на каждом уровне рекурсии).
Есть два способа входа в процедуру:
обычный (характерный для динамического плана), со включением нового этапа в начало плана
независимо от наличия или отсутствия в нем других этапов;
с возобновлением исполнения, при котором значения параметров, указанные при вызове,
игнорируются. Параметры процедуры получают значения, соответствующие первому этапу в плане.
Если план пуст, то возникает ошибочная ситуация, которую можно индицировать, например,
генерацией исключения.
Применение статического плана напоминает программирование с использованием сопрограмм с той
разницей, что для рассматриваемых нами процедур точкой входа всегда является начало процедуры.
Возможна разработка простых или рекурсивных генераторов (на базе глобального или локального
статического плана). Простые генераторы позволят компактно реализовать, например, стек и
очередь для сложных типов данных без явного ввода дополнительных структур (как собственных
так и стандартных, таких как объекты, порожденные по шаблонам STL). Но в первую очередь
статический план необходим при реализации алгоритмов, формирующих промежуточные результаты,
требующие внешней обработки, по завершении которой уже запланированные работы должны быть
продолжены. Сюда относятся схемы поиска с возобновлением, в частности, поиск кратчайших
путей от одной исходной точки до нескольких конечных по волновому алгоритму Ли, где
промежуточным результатом будет путь до очередной точки.
3. Передача параметров. Редукция
Необходимо также дать новую трактовку основным правилам передачи параметров
в процедуры с повторным входом. Параметры, передаваемые по значению, могут
быть использованы тем же образом и по тем же правилам, что и при вызове обычных процедур.
Изменения затрагивают лишь параметры, передаваемые по ссылке, позволяющие
возвращать в вызывающую программу некоторое значение. Предлагается ввести возможность
редукции для таких параметров, обозначаемую наличием специального
модификатора с указанием коммутативной бинарной операции/функции редукции.
Результатом редукции является результат применения указанной операции/функции к множеству
значений данного параметра, полученных в ходе выполнения различных этапов плана.
При отсутствии необходимости в редукции предлагается организовать «туннелирование по умолчанию»
последних значений таких параметров между последовательными вызовами процедуры.
В некоторых случаях может иметь смысл разрыв такой цепи передачи (отсечение) путем
явного указания значений таких параметров на очередном этапе вызова.
Сформулируем следующие простые правила:
если при планировании этапа было затребовано отсечение, то при входе в процедуру,
соответствующем данному этапу, параметр, передаваемый по ссылке, получит значение, явно указанное
при планировании этапа;
если при планировании этапа отсечения не предполагалось, то при соответствующем входе в
процедуру, параметр, передаваемый по ссылке, будет иметь значение, полученное при завершении
предшествующего этапа (после очередного выхода из процедуры);
при возврате в вызывающую программу фактический параметр, переданный по ссылке, будет
иметь значение, полученное на последнем этапе исполнения процедуры с повторным входом.
4. Цепи процедур с планированием повторного входа Рассмотрим алгоритмы, имеющие несколько последовательно зависимых (стадийных) или
полностью независимых (параллельных) сегментов решения, каждый из которых предполагает генерацию
и исполнение серии подзадач. В случае стадийных алгоритмов набор подзадач одного сегмента тем или
иным образом определяет множество подзадач в другом сегменте. Стадийную форму
могут иметь, например,
некоторые алгоритмы работы с двоичным деревом, включающие его обход и выполнение дополнительных
операций. Назовем алгоритмы: а) поиска минимального и максимального элементов, б) нахождения
по отдельности сумм правых и левых элементов. К алгоритмам с независимыми сегментами решения
отнесем задачи обработки множества данных, каждый элемент которого включает несколько
самостоятельных компонентов, например, векторов и матриц.
Пусть каждый сегмент решения реализуется отдельной процедурой
с повторным входом. В случае стадийного решения этапы плана для очередного сегмента
формируются (в том или ином заданном порядке) при исполнении плана предыдущего сегмента.
Тогда все вышеуказанные алгоритмы, независимо от наличия зависимостей между сегментами,
достаточно естественно могут быть реализованы цепью процедур с планированием повторного
входа, в которой каждая процедура реализует один из сегментов решения и может являться
генератором плана для следующей процедуры в цепи.
Для первой процедуры в цепи присутствие начального этапа в плане, инициирующего
генерацию последующих этапов, является обязательным. Для прочих процедур такое условие отсутствует,
поскольку возможна оперативная генерация начальных этапов предшествующей в цепи процедурой.
5. Синтаксис процедур (void-функций) с планированием повторного входа в языке C/C++
Пусть возможность планирования повторного входа будет существовать лишь
для процедур (точнее, void-функций в терминах C/C++). Предлагается ввести в язык несколько
новых ключевых слов и функций, а также расширить трактовку служебного символа "!" и ключевых
слов static и continue.
Заголовок процедуры с повторным входом имеет формат:
Любое из ключевых слов reenterable или chain свидетельствует об отсутствии
возвращаемого результата (процедура) и о возможности повторного входа. Наличие static
(или static global) означает применение глобального статического плана,
static local — локального статического, отсутствие
static — динамического. Если максимальное количество
этапов не указано, то план может иметь произвольный размер. Ключевое слово chain
подразумевает, что текущая процедура обладает динамическим планом и может являться элементом цепи.
Интерфейсом процедуры назовем список формальных параметров, которым должна обладать
следующая в цепи процедура. Возможна явная спецификация интерфейса после ключевого
слова throw. При ее отсутствии считается, что интерфейс процедуры совпадает с ее
списком формальных параметров.
Наличие модификатора reduction с указанием знака бинарной
операции или имени бинарной функции перед декларацией параметра детерминирует необходимость
редукции его значений с применением данной операции/функции.
Обычный вызов процедуры с повторным входом записывается в той же форме, что и
вызов любой процедуры (void-функции) C/C++. Вызов с возобновлением исполнения отличается наличием
ключевого слова continue перед именем процедуры. Для идентификации способа вызова внутри
процедуры предлагается ввести системную функцию plan_after_continue(), которая возвращает
false при обычном вызове и true при возобновлении.
Включение нового этапа в конец плана исполнения реализуется обращением к системной
функции plan_last, которая существует лишь в пределах текущей процедуры с повторным входом
и имеет эквивалентный список формальных параметров. Значения, указанные в списке параметров при
вызове plan_last, станут значениями параметров процедуры на этапе, спланированном при
данном вызове, с вышеуказанными оговорками относительно параметров, передаваемых по ссылке.
Включение нового этапа в начало плана исполнения реализуется обращением к
системной функции plan_first с теми же областью видимости, параметрами и правилами их
передачи, что и при вызове plan_last.
Директива clear_plan очищает план исполнения в пределах текущей
процедуры. Такая возможность может быть востребована в алгоритмах, предусматривающих досрочное
завершение запланированных работ (например, при работе с волновым алгоритмом Ли необходимо
прекратить анализ оставшихся элементов "волны", если кратчайший путь найден).
Системная переменная plan_empty принимает истинное значение, если
план исполнения пуст.
Прекращение исполнения плана реализуется директивой plan_stop. Ее
исполнение не приводит к немедленному выходу из процедуры, но сигнализирует, что после
завершения текущего этапа плана должен произойти возврат в вызывающую программу. При возврате
динамический план очищается, а статический - сохраняется, что дает возможность повторного входа
в процедуру с возобновлением исполнения плана.
Если при планировании некоторого этапа необходим разрыв (отсечение) цепи
передачи параметра по ссылке, то предлагается указывать символ "!" непосредственно после
значения соответствующего фактического параметра при обращении к функциям plan_first
и plan_last.
6. Запуск цепи
В однопроцессорном варианте процедуры цепи запускаются последовательно,
причем каждая из них работает вплоть до исчерпания собственного плана исполнения.
Источником этапов плана может быть как сама процедура, так и предшествующая ей
в цепи процедура. Чтобы обеспечить запуск цепи, ее первая процедура должна быть
выполнена не менее одного раза, следовательно, всегда должна иметь начальный этап
в плане исполнения. Остальным процедурам такой этап необходим лишь в некоторых
случаях, например, для общей инициализации. Потребность в такой инициализации
определяется первым параметром конструкции запуска цепи процедур с повторным входом:
Формат описателя цепи предусматривает два случая, когда цепь
включает последовательность вызовов: а) произвольных процедур; б) одной и той же
процедуры. Во втором случае указывается формат вызова процедуры и длина
(количество элементов) цепи.
Все процедуры цепи не только должны быть декларированы
с ключевым словом chain, но и являться совместимыми — интерфейс любой процедуры
должен совпадать по количеству и типам элементов со списком формальных параметров
следующей в цепи процедуры. Параметры, указанные в вызовах процедур, определяют
содержание начальных (инициализационных) этапов плана исполнения соответствующих
процедур, если такие этапы предусмотрены логикой запуска цепи. Инициализационный
этап всегда выполняется процедурой первым, независимо от того, были ли уже
поступления в план от предыдущей в цепи процедуры.
Помещение нового этапа в начало плана следующей по цепи процедуры
осуществляется обращением к функции throw_first, которая существует в пределах
текущей процедуры и имеет список формальных параметров, эквивалентный интерфейсу
данной процедуры. Включение нового этапа в конец плана следующей процедуры
реализуется обращением к функции throw_last с теми же областью видимости и параметрами.
7. Процедуры с повторным входом в параллельном программировании
В нескольких словах: вводятся операции, позволяющие разделить план
исполнения на группы. Каждая группа изначально запускается на одном процессоре, однако
возможно переключение в параллельный режим, где все процессоры системы будут, по мере
освобождения, "брать" на исполнение этапы из очередной группы. Завершение обработки
группы эквивалентно точке барьерной синхронизации.
Разделение плана на группы осуществляется с помощью маркеров, которые
можно поместить в начало или в конец плана директивами plan_group_first или
plan_group_last соответственно.
Переключение исполнения группы в параллельный режим осуществляется
директивой plan_group_parallelize.
Функция plan_processor_id() возвращает логический номер процессора
(ядра) системы, на котором исполняется текущий этап плана. При работе с одноядерной
вычислительной системой новые ключевые слова просто игнорируются, а функция plan_processor_id()
всегда возвращает номер единственного процессора (например, ноль).
Возможна интеграция в различные расширения языка C/C++, позволяющими
распараллеливать вычисления. Например, при интеграции в OpenMP вместо plan_group_first,
plan_group_last и plan_group_parallelize, соответственно, возможно появление
директивы:
#pragma omp [parallel] plan (first|last|parallelize)
8. Цепи процедур. Векторный и конвейерный параллелизм.
В нескольких словах.
Для реализации векторного параллелизма логичным решением является введение механизма
параллельного запуска для цепи процедур с общей инициализацией. Не менее логично и естественно
может быть реализован конвеерный параллелизм: параллельный запуск процедур цепи
обеспечивается тем же механизмом, причем конвеерная передача данных фактически реализуется
путем вставки дополнительных этапов в начало (throw_first) или конец
(throw_last) плана следующей в цепи процедуры. При этом первая процедура
цепи обязательно выполняется хотя бы один раз, что обеспечивает запуск конвеера,
для прочих элементов цепи такая инициализация является опциональной.
Запуск цепи в параллельном режиме реализуется
путем указания ключевого слова plan_parallel_chain вместо
plan_chain. Все процедуры цепи запускаются одновременно. Цепь завершает
работу, когда завершили работу все ее процедуры (их планы исчерпаны). В ходе работы
процедура цепи или находится в состоянии ожидания, если ее план пуст, или работает
в соответствии с очередным этапом плана.
9. Примеры
9.1. Последовательная нумерация узлов дерева по тройкам "родитель-потомки".
В пределах тройки нумерация -- родитель -> потомок слева -> потомок справа.
typedef struct TreeTag {
int Data;
struct TreeTag * Left;
struct TreeTag * Right;
} TreeNode;
reenterable EnumerateByFamilies(TreeNode * Cur,
char Level, int &Number)
{
Cur->Data = Number++;
if (Level) {
if (Cur->Left) plan_last(Cur->Left,0,Number);
if (Cur->Right) plan_last(Cur->Right,0,Number);
}
else {
if (Cur->Right) plan_first(Cur->Right,1,Number);
if (Cur->Left) plan_first(Cur->Left,1,Number);
}
}
/* Вызов:
int Number = 1;
EnumerateByFamilies(Root,0,Number); */
9.2. Очередь (queue), каждый элемент которой включает два значения
(целочисленное и вещественное). При обычном обращении к процедуре queue осуществляется
помещение значения в очередь, а при вызове с возобновлением - извлечение.
reenterable static queue(int &Int, double &Dbl) {
if (!plan_after_continue()) plan_last(Int,Dbl);
plan_stop;
}
/* Помещение в очередь пары (A,B): queue(A,B); */
/* Извлечение пары (A,B): continue queue(A,B); */
9.3. Две версии рекурсивного генератора, последовательно выдающего
узлы дерева (в порядке левостороннего обхода).
typedef struct TreeTag {
int Data;
struct TreeTag * Left;
struct TreeTag * Right;
} TreeNode;
enum {entryWT, yieldWT, anyWT};
reenterable static local WalkTreeGen(TreeNode * Cur, char Point,
TreeNode * &Out) {
switch (Point) {
case entryWT:
if (Cur->Left)
{
if (Out) continue WalkTreeGen(Cur->Left,entryWT,Out);
else WalkTreeGen(Cur->Left,entryWT,Out);
if (Out)
{
plan_first(Cur,entryWT,Cur!);
plan_stop;
return;
}
}
Out = Cur;
plan_first(Cur,yieldWT,NULL!);
plan_stop;
return;
case yieldWT:
if (Cur->Right)
{
if (Out) continue WalkTreeGen(Cur->Right,entryWT,Out);
else WalkTreeGen(Cur->Right,entryWT,Out);
if (Out) plan_first(Cur,yieldWT,Out!);
plan_stop;
}
}
}
reenterable static local WalkTreeGen(TreeNode * Cur, char Point,
TreeNode * &Out) {
switch (Point) {
case entryWT:
if (Cur->Left)
{
if (Out) continue WalkTreeGen(Cur->Left,entryWT,Out);
else WalkTreeGen(Cur->Left,entryWT,Out);
if (Out)
{
plan_first(Cur,entryWT,Cur!);
plan_stop;
return;
}
}
Out = Cur;
plan_first(Cur,yieldWT,NULL!);
plan_stop;
return;
case yieldWT:
if (Cur->Right)
plan_first(Cur->Right,entryWT,NULL!);
}
}
9.4. Применение цепей. Последовательная нумерация узлов двоичного дерева по уровням снизу вверх и справа налево.
Алгоритм реализуется в два этапа (соответственно, используем цепь из двух элементов): планирования обхода элементов сверху вниз и слева направо в процедуре
Rev1 с последующим формированием эквивалентного плана, но с этапами, идущими в обратном порядке, для процедуры последовательной нумерации
Rev2.
typedef struct TreeTag {
int Data;
struct TreeTag * Left;
struct TreeTag * Right;
} TreeNode;
chain Rev1(TreeNode* Cur) throw(TreeNode* Cur, int &Number) {
if (Cur->Right) plan_last(Cur->Right);
if (Cur->Left) plan_last(Cur->Left);
throw_first(Cur,1);
}
chain Rev2(TreeNode * Cur, int &Number) {
Cur->Data = Number++;
}
/* Вызов (Root — указатель на корневой элемент дерева):
int Number = 1;
plan_chain(0,Rev1(Root),Rev2(Root,Number));
*/
9.5. Цепи (стадийный алгоритм). Волновой алгоритм Ли поиска кратчайшего пути в лабиринте.
В таком алгоритме на первой стадии моделируется распространение кольцевой волны (клетки лабиринта
получают номера, соответствующие номерам очередного фронта волны) от начальной точки. Как только волна
достигает конечной точки, путь найден. Для его выделения осуществляется последовательный переход
из конечной точки в начальную таким образом, чтобы каждая следующая клетка пути имела номер, меньший
чем у текущей клетки. Т.о. клетки кратчайшего пути определяются в обратном порядке. Чтобы вывести их
в прямом порядке, необходима инверсия, реализуемая путем введения второй стадии алгоритма.
При этом найденные (в обратном порядке) клетки пути передаются в план второй стадия алгоритма
в обратном порядке. Поэтому вторая стадия алгоритма выводит найденные клетки в прямом порядке.
Это достаточно хорошая иллюстрация целесообразности применения операций throw_first,
throw_last в обычной цепи (без параллелизма) для реализации стадийного алгоритма.
const int NL = 10; /* Размер лабиринта */
const unsigned char W = 0xFF; /* Стенка */
/* Лабиринт */
unsigned char Labirint[NL][NL] =
{
{W,W,W,W,W,W,W,W,W,W},
{W,0,0,0,0,0,0,0,0,W},
{W,0,W,W,0,0,W,0,0,W},
{W,0,0,W,0,0,W,0,0,W},
{W,0,0,W,W,0,W,0,0,W},
{W,0,0,0,W,W,W,0,0,W},
{W,0,0,0,0,0,0,0,0,W},
{W,0,0,0,0,0,0,0,0,W},
{W,0,0,0,0,0,0,0,0,W},
{W,W,W,W,W,W,W,W,W,W},
};
/* Приращения для сдвига относительно текущей клетки
влево, вверх, вниз, вправо */
signed char OffsX[4] = {-1,0,0,+1};
signed char OffsY[4] = {0,-1,+1,0};
const char FirstX = 8; /* Точка отправления */
const char FirstY = 8;
const char LastX = 5; /* Точка назначения */
const char LastY = 4;
chain[NL*NL] FindLi(unsigned char X, unsigned char Y, int Num)
throw(unsigned char X, unsigned char Y) {
char Found = 0;
Labirint[Y][X] = Num++;
for (int i=0; !Found && i<4; i++) { /* Просматриваем клетки рядом */
unsigned char X1 = X+OffsX[i];
unsigned char Y1 = Y+OffsY[i];
if (X1>=0 && X1<NL && Y1>=0 && Y1<NL && Labirint[Y1][X1]==0) {
/* Если клетка еще не пронумерована */
Labirint[Y1][X1] = Num; /* Нумеруем */
if (X1==LastX && Y1==LastY) /* Если последняя */
Found = 1; /* Сигнализируем окончание */
else /* Если не последняя */
plan_last(X1,Y1,Num); /* Помещаем в очередь просмотра */
}
}
if (Found) {
clear_plan; /* Очищаем план просмотра клеток */
X = LastX; Y = LastY;
/* Помещаем в план следующей стадии ("стек") последнюю точку назначения */
throw_last(X,Y);
/* Пока не дошли до точки отправления */
while (X!=FirstX || Y!=FirstY) {
char PointFound = 0; /* Поиск следующей клетки пути */
for (int i=0; !PointFound && i<4; i++) {
/* Кандидат на следующую клетку пути */
unsigned char X1 = X+OffsX[i];
unsigned char Y1 = Y+OffsY[i];
if (X1>=0 && X1<NL && Y1>=0 && Y1<NL && Labirint[Y1][X1] &&
Labirint[Y1][X1]<Labirint[Y][X]) {
/* Если клетка не пуста и имеет меньший номер */
/* У клеток стенок самые большие номера, в рассмотрение не попадают */
PointFound = 1;
/* Добавляем в путь (стек) найденную клетку */
throw_first(X1,Y1);
/* На следующем шаге будем исходить из этой клетки */
X = X1; Y = Y1;
}
}
}
} else if (plan_empty)
cout<<"NO PATH\n"; /* Не дошли до места назначения */
}
chain[NL*2] OutLi(unsigned char X, unsigned char Y) {
cout<<"("<<(int)Y<<","<<(int)X<<") ";
}
/* Вызов:
plan_chain(0,FindLi(FirstX,FirstY,1),OutLi(0,0));
*/
9.6. Параллельная реализация алгоритма поиска максимального элемента в
дереве с корнем Root. Узлы дерева представляют собой элементы данных типа
TreeNode,
константа nProcs - количество ядер в системе. Поиск в параллельном варианте представлен
процедурой с повторным входом _TreeMax, функция TreeMax (с параметром - указателем на
корень дерева) обобщает частные результаты поиска по всем процессорам и возвращает конечный
результат.
int MaxResult[nProcs];
reenterable _TreeMax(TreeNode * Cur) {
int thread_id = plan_processor_id();
if (Cur==Root) plan_group_parallelize;
if (Cur->Left) plan_last(Cur->Left);
if (Cur->Right) plan_last(Cur->Right);
if (MaxResult[thread_id]<Cur->Data)
MaxResult[thread_id] = Cur->Data;
}
int TreeMax(TreeNode * Root) {
int Result;
memset(MaxResult,0,sizeof(MaxResult));
_TreeMax(Root);
Result = MaxResult[0];
for (int i=1; i<nProcs; i++)
if (MaxResult[i]>Result) Result = MaxResult[i];
return Result;
}
9.7. Редукция. Реализация алгоритма параллельного суммирования элементов в дереве с корнем Root.
reenterable TreeSum(TreeNode * Cur, reduction(+) DataItem & SumResult) {
if (Cur==Root) plan_group_parallelize;
if (Cur->Left) plan_last(Cur->Left,SumResult);
if (Cur->Right) plan_last(Cur->Right,SumResult);
SumResult = Cur->Data;
}
9.8. Конвейерный параллелизм (цепь). Реализация алгоритма поиска максимального и
минимального элементов в дереве с корнем Root. Узлы дерева представляют собой элементы данных типа
TreeNode,
константа nProcs - количество ядер в системе.
Примечательно, что в данном алгоритме
продемонстрирована еще одна возможность предложенного формализма: на каждой стадии конвейера может
работать несколько процессоров. При этом план для каждой процедуры-стадии распараллеливается точно таким же
образом, как и для обычной процедуры с повторным входом: задействованные процессоры, по мере
освобождения, берут этапы исполнения из плана. Для достижения такого эффекта используется явное
указание количества процессоров на стадию:
вызов_процедуры / количество_процессоров
int MaxResult[nProcs];
/* Первая стадия конвейера -- поиск максимума */
chain _TreeMax(TreeNode * Cur)
{
int thread_id = plan_processor_id();
throw_last(Cur); /* Ссылку на текущий элемент перебрасываем на следующую
стадию конвейера (для поиска минимума) */
if (Cur==Root) plan_group_parallelize; /* Это необходимо, если на текущей
стадии конвейера параллельно работает более одного процессора */
/* Планируем обход дерева */
if (Cur->Left) plan_last(Cur->Left);
if (Cur->Right) plan_last(Cur->Right);
if (MaxResult[thread_id]<Cur->Data)
MaxResult[thread_id] = Cur->Data;
}
int MinResult[nProcs];
/* Вторая стадия конвейера -- поиск минимума */
chain _TreeMin(TreeNode * Cur)
{
int thread_id = plan_processor_id();
if (Cur==Root) plan_group_parallelize; /* Это необходимо, если на
текущей стадии конвейера параллельно работает более одного процессора */
if (Cur->Data<MinResult[thread_id])
MinResult[thread_id] = Cur->Data;
}
/* Функция поиска минимума и максимума */
int TreeMinMax(int PerStageNP, int & Min)
{
int Result;
int i;
for (i=0; i<nProcs; i++) {
MaxResult[i] = 0;
MinResult[i] = 100000;
}
/* Запускаем параллельное исполнение цепи из двух стадий, на каждой
стадии задействуем PerStageNP процессоров */
plan_parallel_chain(0,_TreeMax(Root)/PerStageNP,_TreeMin(Root)/PerStageNP);
/* Собираем результаты */
Min = MinResult[0];
Result = MaxResult[0];
for (i=1; i<(PerStageNP ? PerStageNP : 1); i++)
{
if (Result<MaxResult[i]) Result = MaxResult[i];
if (MinResult[i]<Min) Min = MinResult[i];
}
return Result;
}
/* Вызов (Root — указатель на корневой элемент дерева,
PerStageNP - количество процессоров на одну стадию конвейера):
int Min, Max;
Max = TreeMinMax(PerStageNP,Min);
*/
void _Out(TreeNode * Cur) {
list<TreeNode *> Queue =
list<TreeNode *>();
int LevelNodes = 1;
int NextLevelNodes = 0;
Queue.push_back(Cur);
while (!Queue.empty()) {
Cur = Queue.front();
Queue.pop_front();
cout<<Cur->Data()<<" ";
if (Cur->Left) {
Queue.push_back(Cur->Left);
NextLevelNodes++;
}
if (Cur->Right) {
Queue.push_back(Cur->Right);
NextLevelNodes++;
}
if (--LevelNodes==0) {
cout<<"\n";
LevelNodes = NextLevelNodes;
NextLevelNodes = 0;
}
}
}
int CurLevel = 1;
reenterable Out(TreeNode* Cur,int Level) {
if (Level!=CurLevel) {
CurLevel = Level;
cout<<"\n";
}
cout<<Cur->Data()<<" ";
if (Cur->Left)
plan_last(Cur->Left,Level+1);
if (Cur->Right)
plan_last(Cur->Right,Level+1);
}
Параллельный конвейерный расчет векторного выражения X1+X2*X3 для массива из
K элементов (X1,X2,X3). X1,X2,X3 — массивы [K][VEC_SIZE]. R — результаты [K][VEC_SIZE]
Классический вариант. OpenMP
Цепь процедур с
повторным входом
int NLOCK = 0;
#pragma omp parallel num_threads(2)
private(i) shared(NLOCK)
switch (omp_get_thread_num()) {
case 0:
for (i=0; i<K; i++) {
R[i][0] = 0.0;
for (j=0; j<VEC_SIZE; j++)
R[i][0] += X2[i][j]*X3[i][j];
#pragma omp atomic
NLOCK++;
#pragma omp flush(NLOCK)
}
break;
case 1:
for (i=0; i<K; i++) {
while (NLOCK<i) _Yield();
for (j=VEC_SIZE-1; j>=0; j--)
R[i][j] = X1[i][j]+R[i][0];
}
}
chain St0(int N, double*V1,double*V2,double*V3,
double*R) throw(double*V1,double MUL,double*R) {
for (int i=0;i<N;i++,V1+=VEC_SIZE,R+=VEC_SIZE) {
double MUL = 0.0;
for (int j=0; j<VEC_SIZE; j++)
MUL += (*V2++)*(*V3++);
throw_last(V1,MUL,R);
}
}
chain St1(double* V1, double MUL, double* R) {
for (int j=0; j<VEC_SIZE; j++)
R[j] = V1[j]+MUL;
}
/* Вызов */
plan_parallel_chain(0,St0(K,(double*)X1,(double*)
X2,(double*)X3,(double*)R),St1(NULL,0,NULL));
модуль отображения результатов расчета в графической форме;
модуль оперативной адаптации базовой математической модели
под решаемую задачу (используются технологии порождения программ).
Расчетный блок предназначен для работы в средах Linux, Solaris,
Windows, имеются однопроцессорный и многопроцессорный варианты
(гетерогенные кластеры, системы МВС-1000, Parsytec).
Прочие модули работают в среде Windows.
В настоящее время система применяется преимущественно
для численного моделирования процессов образования
и распространения твердых, жидких и газообразных
загрязнителей в воздушной среде.
Обеспечивается повышение точности оценки уровней загрязнений
на улицах города и в окрестности предприятий; прогнозирование
последствий чрезвычайных ситуаций, связанных с крупномасштабным
выбросом загрязнителей.
Возможности расчета
расчет динамики турбулентной среды в трехмерной рабочей области
с использованием
уравнений Навье-Стокса для несжимаемой
вязкой среды в переменных "скорость-давление",
модели турбулентности K-E (вариант RNG),
уравнений диффузии газов и переноса пылевых частиц;
расчет изменений концентраций веществ в результате происходящих
химических реакций (решаются обыкновенные дифференциальные
уравнения химической кинетики), что позволяет моделировать вторичное
загрязнений в экологических задачах;
расчет конденсации, испарения, поглощения загрязнителей каплями,
что позволяет моделировать образование кислотных дождей;
распространение излучения и его влияние на тепловые
и фотохимические процессы.
Особенности системы
реализован оригинальный алгоритм расчета капельных фаз,
отличающияся относительно невысокими трудозатратами;
используются специальные методики распараллеливания,
позволяющие добиться 90-95% эффективности расчета;
комбинирование интерфейсов распараллеливания MPI и OpenMP
повышает эффективность расчетов на многопроцессорных
кластерных системах, состоящих из блоков с общей памятью
(многопроцессорных и/или многоядерных);
возможно оперативное изменение рабочей математической модели
в визуальном режиме (составляется графическая схема задачи),
что обеспечивается применением авторских технологий порождения
программ.
Опыт расчетов
Проводилось численное моделирование процессов
образования и распространения фотохимического смога на улице города.
Использовались опытные данные о выделении загрязнений на улице
Göttinger Straße (Ганновер) и стандартная модель смога
CBM-IV (36 реагентов, 83 реакции). Учтены тепловые эффекты,
связанные с поглощением излучения, лучистым теплообменом со стенами
зданий. Получены распределения наиболее опасных компонентов смога:
озона, пероксиацетилнитрата, паров азотной кислоты.
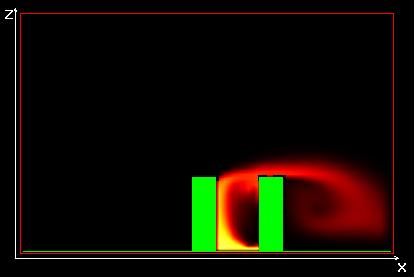
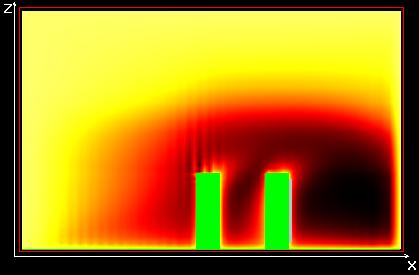
Концентрации озона в горизонтальном сечении
Распределение температуры в горизонтальном сечении
Концентрации озона в фронтальном сечении
Распределение температуры во фронтальном сечении
Апробация
Проводились эксперименты по моделированию
распространения инертного загрязнителя на улице
Göttinger Straße (Ганновер). Результаты расчетов сравнивались
с данными, полученными в ходе аналогичных расчетов в рамках
проекта TRAPOS
(Traffic Polution in Streets) с применением схожих систем.
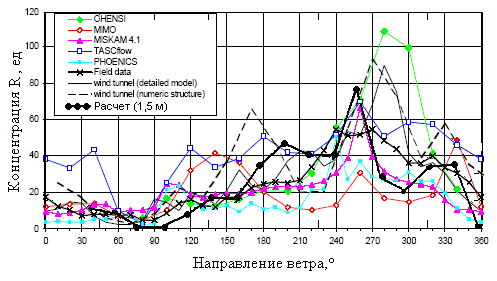
Наш расчет (AirEcology-P) занимает
первое/второе места по ряду частных показателей и второе место
в общем рейтинге систем (TASCflow, AirEcology-P, Chensi, MIMO,
Miskam, Phoenics). На графике показаны безразмерные концентрации
загрязнителя в контрольной точке, полученные при различных
направлениях ветра.
Также расчитывались поля
загрязнений в окрестности предприятий.
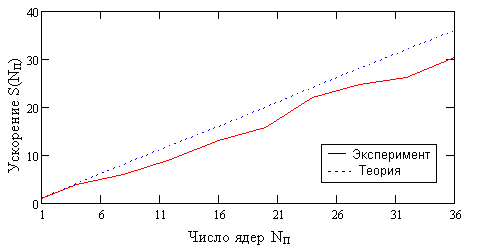
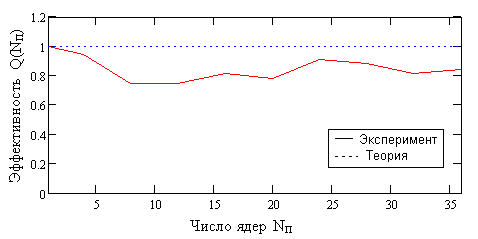
Расчет на многопроцессорных системах
Показано хорошее ускорение и высокая эффективность
расчетов в расчетах на
кластерной системе ИГЭУ. При использовании 36 процессоров удалось
получить ускорение в 31 раз.
Ускорение на кластере ИГЭУ (OpenMP+MPI) при различных числах ядер
Эффективность распараллеливания на кластере ИГЭУ (OpenMP+MPI)
при различных числах ядер
Полная или частичная автоматизация программирования --
давняя мечта теоретиков. "Философский камень программирования",
проблема, которую неоднократно пытались решить самыми различными
методами и так и не решили в полной мере. Тем не менее, это не
фикция и не полная утопия. Работы в данном направлении продолжаются
и нельзя сказать, что задача умерла, не дожив до решения.
В этом полушутливом введении автор немного
иронизировал. Самоирония полезна, когда рассказываешь
о своих попытках решения задач высокой и сверхвысокой сложности.
Из того факта, что задача очень сложна, вовсе
не следует, что она неразрешима. Правильнее было бы сказать, что
она вряд ли может быть решена в полной мере на данном этапе
развития технологий искусственного интеллекта. Однако можно
вполне успешно находить решения, частично автоматизирующие
программирование для определенных классов задач.
Таких решений много:
системы прямого преобразования описания в код (Draco, TAMPR),
которые описывают последовательность трансформаций с помощью
специальных средств,
компилирующие шаблоны (Software Factories), в которых описание задачи
строится в виде блочной схемы, а затем пишется небольшой компилятор,
который делает ряд запросов к структуре модели и на основании
полученных результатов генерирует программу,
прямое исполнение описания задачи (заданного в виде сети
объектов) на виртуальной машине (Флора/FloraWare),
решающие системы (ПРИЗ, IPGS), в которых человек ставит задачу
в виде "цели->результат", а система находит путь решения такой
задачи (с помощью поиска в пространстве состояний) и порождает
соответствующий код,
автоматное описание (SWITCH-технологии), где логика задачи
описывается в виде множества состояний и связей/переходов между ними,
что позволяет сгенерировать нужный код,
специализированные системы (для конкретных задач),
отчасти, ментальное программирование (IP).
Предлагается решение, в основе которого лежат
идеи, схожие с идеями, реализованными корпорацией Microsoft в
системах класса Software Factories, а также с некоторыми принципами
системы ПРИЗ. Демонстрационную версию можно
скачать здесь, это вариант, интегрированый в систему AirEcology-P,
в качестве генератора фрагментов программы расчетного блока. Прочитать о назначении
и правилах запуска этой версии можно на моей странице демо-версий. Подробное описание системы разрабатывается.
Исходный текст проекта исключен из свободного доступа с 31.08.2017 по просьбе
нового правообладателя (имущественные права на код переданы иному лицу). Возможно ознакомление
с одной из ранних версий проекта в некоммерческих/научных целях (можно связаться по почте pekunov.mail.ru)
на условиях нераспространения.
Теория
Предлагается ввести в операционные системы и среды фоновый алгоримтический слой,
позволяющий по характерным точкам трассы, связанным с метками времени исполнения
и значениями выделенных программой пользователя данных строить модели логики,
данных и временных характеристик функционирования этой программы.
Вводится понятие Метаслоя ОС или ПП, в котором легко организовать анализ
исполнения программы с выработкой рекомендаций по ее дальнейшему функционированию,
а именно: выделению и перераспределению памяти, интеллектуализации или оптимизации
алгоритмов ее исполнения и иных потребных ПП.
Это позволяет выявить скрытый параллелизм ее исполнения
и соответствующим образом распараллелить решение задачи на многопроцессорной или многоядерной
вычислительной системе. Построенные модели данных позволяют осуществлять их предикцию
для опережающего планирования ресурсов или в иных целях. Профилировка выполняется
автоматически.